“Let’s build a database engine.”
I made this custom small database project as part of my Database Management Laboratory final assignment. When I first looked at the list of recommended full-stack projects, I was honestly bored. They all felt too templated. So instead of picking one of those ideas or copying a senior’s project, I decided to do something from scratch—something that sounded cool.
At the time, it felt ambitious. But I’d been curious about how databases actually work under the hood. So this was the perfect excuse to explore that.
KeystoneDB is what came out of that effort.
What is KeystoneDB?
KeystoneDB is a custom-built relational database engine with its own mini-SQL parser and a query executor that talks to a key-value store (RocksDB) underneath.
Here’s what it does:
- It has a hand-written lexer and parser (using Flex and Bison).
- It supports a small SQL-like query language.
- It compiles queries into operations that run against RocksDB.
- It stores data in a log-structured way (somewhat like LSM trees).
Think of it as writing a compiler for a SQL subset and pairing it with a tiny execution engine and storage layer.
Motivation
I wanted to learn how databases really work. I’d heard terms like “query plan,” “transaction log,” “WAL,” “compaction,” “indexing,” etc., but they were just words to me. This project helped connect all that theory to real working code.
Instead of using SQLite or PostgreSQL as a black box, I wanted to build something—even if simple—that could:
- Parse input queries
- Interpret/compile them
- Interact with low-level storage
Learning Curve & Stack
Here’s what I ended up using:
- C++ for the core database engine (tight control + performance)
- RocksDB for persistent key-value storage
- Flex/Bison for writing the SQL-like lexer and parser
- Google Test for unit testing
It wasn’t always smooth. I broke things a lot. RocksDB has a bit of a learning curve, and writing your own SQL parser is surprisingly tricky (especially when dealing with whitespace and multi-line queries). But the learning was worth it.
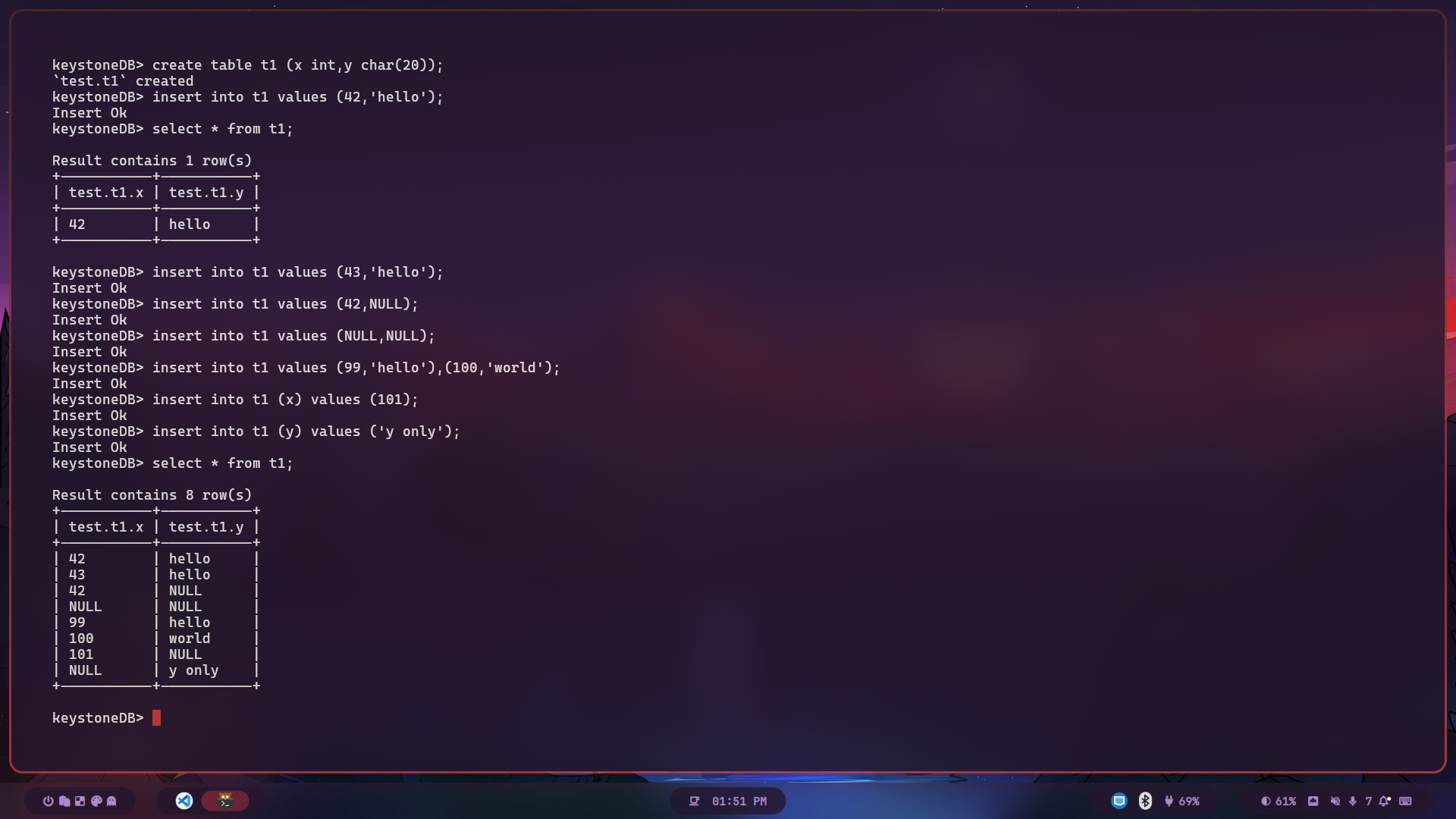
Demo
Here’s a screen shot.
Sample Query
Here’s a glimpse of how it looks:
CREATE TABLE users (id INT, name TEXT);INSERT INTO users VALUES (1, 'Alice');SELECT * FROM users;(You can try similar queries at keystonedb.sumitk.me)
You can also try this custom database with some advanced Queries. I worked upon them a lot to handle all the cases.
create database test;
use test;
create table t1 (x int,y char(20));insert into t1 values (42,'hello');select * from t1;insert into t1 values (43,'hello');insert into t1 values (42,NULL);insert into t1 values (NULL,NULL);insert into t1 values (99,'hello'),(100,'world');insert into t1 (x) values (101);insert into t1 (y) values ('y only');
-- insert test (error expected)-- Char too longinsert into t1 (x,y) values (101,'looooooooooooooooooooooooooooooooooog');-- Data type mismatchinsert into t1 (x,y) values ('100','mismatch');-- Too much argumentinsert into t1 (x) values (1,'column mismatch',99);-- Column count doesn't match value count at row 1insert into t1 values (1);-- Unknown column nameinsert into t1 (not_exist_name) values (1,'not exist name');
create table t2 (x int,y char(20));
insert into t2 values (1,'a'),(2,'b'),(3,'c');
create table t3 (x int,y char(20));
insert into t3 values (4,'d'),(5,'e'),(6,'f');
create table t4 (x int,z char(20));
insert into t4 values (7,'g'),(8,'h'),(9,'i');
-- no ambiguityselect t2.x,t3.x from t2,t3;
-- ambiguous column name xselect x,y from t2,t3;
-- ambiguous column name yselect t2.x,y from t2,t3;
-- infer the table that z belongs toselect t2.x,z from t2,t4;
-- expression evaluationselect * from t2;
select * from t2 where 1=1;select * from t2 where 1=x;select * from t2 where 'a'<y;select * from t2 where 'a'<y and x>2;select * from t2 where ('a'<y and x>2)=x-1;
update t2 set x=x*10 where x =3;select * from t2;
delete from t2 where x=x/x ;select * from t2;
drop table t1;
-- column constraint ( the comment can be filtered)create table t5 (id int not null);insert into t5 values (1),(2);-- column id can not be nullinsert into t5 values (NULL);
-- between expressioncreate table t6 (id int,str char(20));insert into t6 values (1,'abc'),(2,'bcd'),(3,'efg'),(4,'hij');select * from t6 where id between 2 and 4;select * from t6 where 3 between id and 4;
-- showshow databases;show tables;
-- exitexit;Final Thoughts
This project became more than just a lab submission. It was a deep dive into:
- Writing compilers (parsers)
- Working with LSM-tree-based storage
- Understanding query execution
If you’re curious about how databases work or want to build your own toy DB, feel free to check out the code here: github.com/SumitKumar-17/keystoneDB
Let me know if you build something cool with it or have any ideas :)