Building NotebookLM: A Journey Through Dependency Hell
/ 5 min read
My NotebookLM Clone: Chat With Your PDFs
(Live Demo: notebooklm.sumitk.me | Source Code: GitHub)
So I got this assignment: build a web app where you can upload a PDF and chat with it. The AI should find answers from the document and cite the page number. Basically, a clone of Google’s NotebookLM. Seemed straightforward enough.
It turned into a fucking brutal lesson in dependency hell.
The final app works, but the story isn’t about the features—it’s about the fight to get it deployed.
The Stack (The Easy Part)
The initial setup was simple:
- Frontend: Next.js (React) with TypeScript and Tailwind CSS.
- Backend: Convex for the database, file storage, and serverless functions.
- Deployment: Vercel for the frontend, Convex for the backend.
Easy enough. Then came the PDF libraries.
What It’s Supposed To Do (The Happy Path)
The idea is simple. You go to the site, upload a PDF, and you get a split-screen view: PDF on one side, chat on the other.
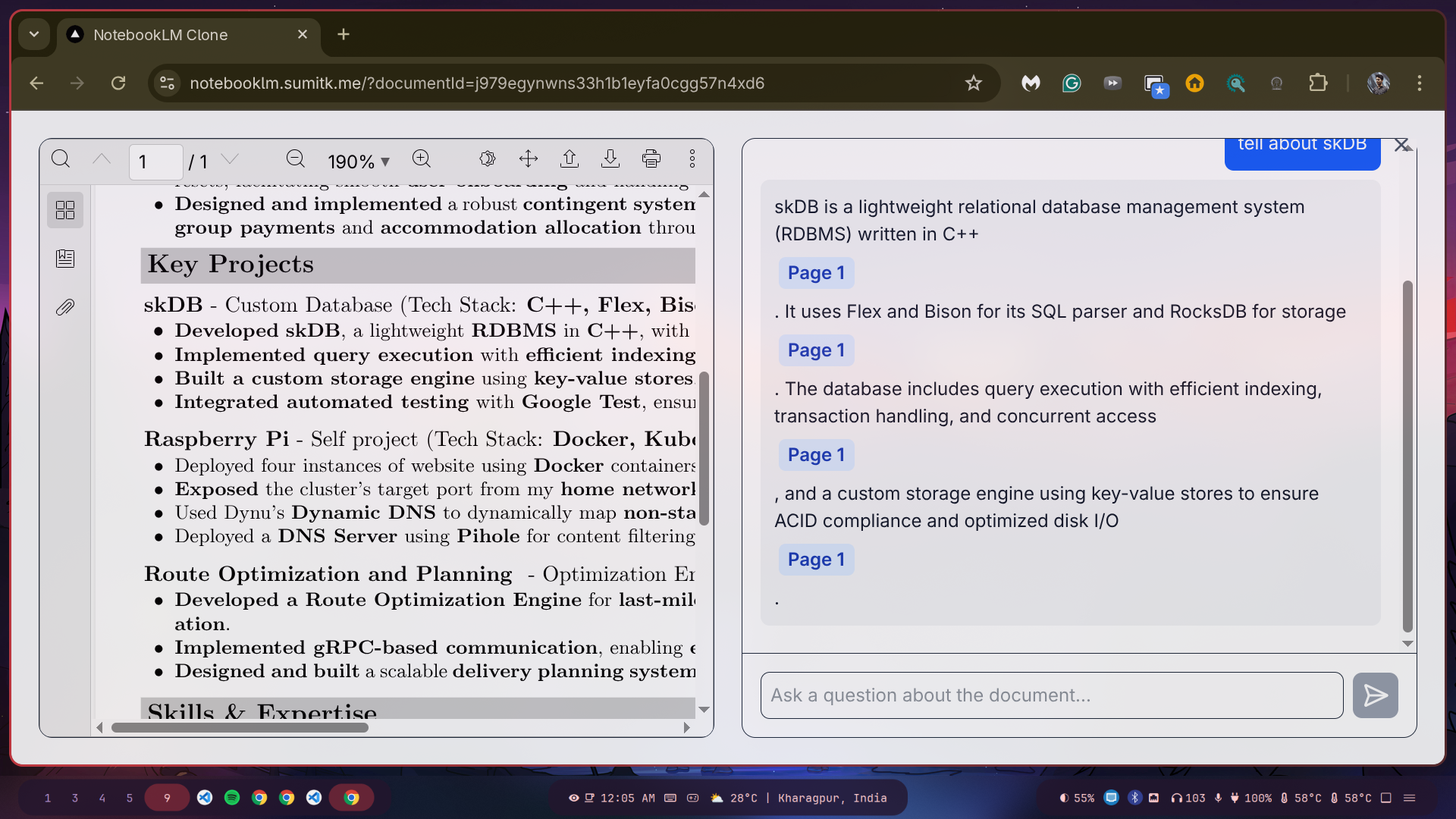
You can ask questions like “What does this document say about project X?” and the AI (using Gemini) reads through the text, finds the answer, and spits it back out with a little [Page: 5] button. You click the button, and the PDF viewer on the left jumps right to that page.
That’s the dream. The reality was a nightmare.
The Brutal Part: A Journey Through PDF Library Hell
To build this thing, you need two key pieces of PDF functionality:
- Backend Parsing: A library to rip the text out of the PDF so the AI can read it.
- Frontend Viewing: A library to actually display the PDF in the browser.
Both turned out to be absolute minefields.
The Parser Saga
My goal was simple: give a function a PDF file, get text back. I tried four different libraries.
-
LlamaParse: The assignment actually hinted at this. It’s powerful and AI-focused. The problem: It works with webhooks. This means your backend needs a public URL, even for local development. This immediately introduces a ton of complexity—ngrok tunnels, CORS issues, making sure your deployed URL is perfect. After hours of debugging webhook failures, I gave up. Too complicated for a simple task.
-
pdf-parse: Okay, fuck the cloud service. Let’s use a simple, popular npm library. The problem: It’s ancient and broken. It has a bug where it literally tries to read its own internal test files (ENOENT: no such file or directory, open './test/data/...') when you try to deploy it. It works locally but shits the bed on the server. Dead end. -
pdfjs-dist(Mozilla’s official library): Fine, I’ll use the core engine that everyone else uses. The problem: It’s a “universal” library, meaning it’s packed with code for both the browser and Node.js. When I imported it on the backend, the Convex bundler saw browser-specific code for rendering canvases (DOMMatrix is not defined) and immediately crashed the build. Another dead end. -
@opendocsg/pdf2md(The Winner): I was about to lose my mind, but then I found this. A simple, modern library with one job: turn a PDF buffer into Markdown. No weird dependencies, no browser code. It just worked. Lesson learned: The best library isn’t always the most popular; sometimes it’s the one that does one thing and doesn’t bring a mountain of baggage with it.
The Viewer Saga
You’d think the frontend would be easier. You’d be wrong. It was the same story.
-
react-pdf: The most popular choice. The problem: Getting its “worker” script to load is a nightmare. First, the import syntax failed the Next.js build (DOMMatrixerror, again). Then, using a CDN link caused CORS errors at runtime. Then, trying to copy the worker file locally with a script failed because the file path kept changing between versions. -
@react-pdf-viewer/core(The Winner): Switched to this alternative. It still had problems—the build failed because it also has a hidden dependency on a package calledcanvas. The final fix was to add a custom Webpack config tonext.config.jsto literally tell the Next.js build process to pretend thecanvaspackage doesn’t exist.
What I Learned From This Project
- Third-party PDF libraries in the JS ecosystem are a mess. Most are old, unmaintained, or built for a different era of web development, not for modern serverless/edge environments.
- “Universal” libraries are a trap. A library that tries to work everywhere (browser, Node.js) often brings browser-specific code that will crash your server-side build.
- Deployment errors are the worst errors. What works on
localhostmeans nothing. The real test is the build server, and it will expose every single flaw in your dependencies. - Sometimes you have to go through four or five libraries to find the one that isn’t broken.
Conclusion
The app is done and it works. It was a massive pain in the ass, but I learned more about Webpack, Next.js build internals, CORS, and Node.js vs. browser runtimes than I ever wanted to. The final stack is solid, but the journey to get there was brutal.
If you’re building something similar, I hope this saves you some pain. Or at least lets you know you’re not alone in the suffering.